
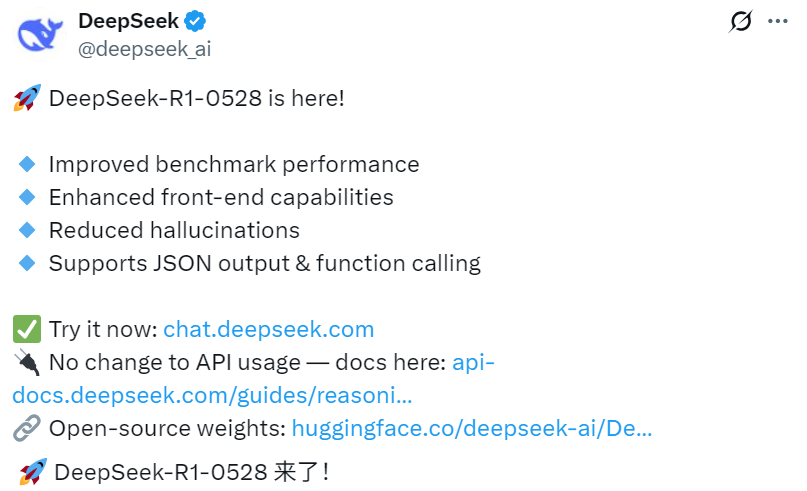
 机器核心报告的编辑:开放模型资源领域的DU WEI,DeepSeek带来了另一个惊喜。上个月28日,DeepSeek收到了一个少量更新,其R1推理模型正在升级到最新版本(0528),并披露了模型和权重。目前,R1-0528进一步提高了基准性能,改善了面部功能,减少幻觉并支持JSON的呼叫和功能。如今,Lmarena是著名行业领导者,但最近有争议的LMARENA的公共基准测试平台被教导,该平台部分在Openai中部分是Google和Meta的大型模型),已发布了最新的性能排名,这是Deviceek-R1(0528)的结果,特别是引人注目的。其中,在文本基准(文本)上,DeepSeek-R1(0528)总体排名第六,并在开放模型中排名之前。特别是在以下子行业中:硬提示测试中的排名第4位在编码测试中排名2在MAT中排名5在创造性写作测试中排名6在两项测试中排名9,在较长的查询测试中排名8,在多转弯测试中排名第7,此外,在WebDev Arena平台上,DeepSeek-R1(0528),与Gemini-1.5-Pro-Pro-ProView-06-05相比,Claude-06-05,Claude-epus 4。挑战网络开发的大型语言模型,衡量人类对美学发展模型和强大的Web应用程序功能的偏好。 DeepSeek-R1(0528)所表现出的强劲表现激起了更多使用Marour Man的渴望。据说,给定的克劳德长期以来一直是AI编程领域的基准,DeepSeek-R1(0528)现在与Claude Opus在Performance中可以媲美,这是一个里程碑,也是开放AI资源的关键时刻。 DeepSeek-R1(0528)在完全开放的MIT协议下提供了最佳性能,并且与最佳的封闭资源模型相媲美s。尽管这种成功在网络的开发中最为明显,但它的影响可以扩展到更广泛的编程领域。但是,RAW的性能并不能确定现实世界的性能。尽管DeepSeek -R1(0528)在技术上可能与Claude相当,但是如果它可以提供与Claude在当天至今的工作流相当的用户体验,则需要更实际的验证。以高强度为基础的DeepSeek-R1(0528)可以在评论领域留言并讨论他们的经历。
机器核心报告的编辑:开放模型资源领域的DU WEI,DeepSeek带来了另一个惊喜。上个月28日,DeepSeek收到了一个少量更新,其R1推理模型正在升级到最新版本(0528),并披露了模型和权重。目前,R1-0528进一步提高了基准性能,改善了面部功能,减少幻觉并支持JSON的呼叫和功能。如今,Lmarena是著名行业领导者,但最近有争议的LMARENA的公共基准测试平台被教导,该平台部分在Openai中部分是Google和Meta的大型模型),已发布了最新的性能排名,这是Deviceek-R1(0528)的结果,特别是引人注目的。其中,在文本基准(文本)上,DeepSeek-R1(0528)总体排名第六,并在开放模型中排名之前。特别是在以下子行业中:硬提示测试中的排名第4位在编码测试中排名2在MAT中排名5在创造性写作测试中排名6在两项测试中排名9,在较长的查询测试中排名8,在多转弯测试中排名第7,此外,在WebDev Arena平台上,DeepSeek-R1(0528),与Gemini-1.5-Pro-Pro-ProView-06-05相比,Claude-06-05,Claude-epus 4。挑战网络开发的大型语言模型,衡量人类对美学发展模型和强大的Web应用程序功能的偏好。 DeepSeek-R1(0528)所表现出的强劲表现激起了更多使用Marour Man的渴望。据说,给定的克劳德长期以来一直是AI编程领域的基准,DeepSeek-R1(0528)现在与Claude Opus在Performance中可以媲美,这是一个里程碑,也是开放AI资源的关键时刻。 DeepSeek-R1(0528)在完全开放的MIT协议下提供了最佳性能,并且与最佳的封闭资源模型相媲美s。尽管这种成功在网络的开发中最为明显,但它的影响可以扩展到更广泛的编程领域。但是,RAW的性能并不能确定现实世界的性能。尽管DeepSeek -R1(0528)在技术上可能与Claude相当,但是如果它可以提供与Claude在当天至今的工作流相当的用户体验,则需要更实际的验证。以高强度为基础的DeepSeek-R1(0528)可以在评论领域留言并讨论他们的经历。


